Sometimes, I randomly browse through Go source code just to look for any patterns or best practices. I was doing that recently with the log package when I came across an interesting observation that I wanted to share.
Any call to log.Print or log.Println or any of its sister functions is actually a wrapper around the equivalent S call from the fmt package. The final output of that is then passed to an Output function, which is actually responsible for writing out the string to the underlying writer.
Here is some code to better explain what I’m talking about -
// Print calls l.Output to print to the logger.// Arguments are handled in the manner of fmt.Print.func(l*Logger)Print(v...interface{}){l.Output(2,fmt.Sprint(v...))}// Println calls l.Output to print to the logger.// Arguments are handled in the manner of fmt.Println.func(l*Logger)Println(v...interface{}){l.Output(2,fmt.Sprintln(v...))}
This means that if I just have one string to print, I can directly call the Output function and bypass this entire Sprinting process.
Lets whip up some benchmarks and analyse exactly how much of an overhead is taken by the fmt call -
func BenchmarkLogger(b *testing.B) {
logger := log.New(ioutil.Discard, "[INFO] ", log.LstdFlags)
errmsg := "hi this is an error msg"
for n := 0; n < b.N; n++ {
logger.Println(errmsg)
}
}
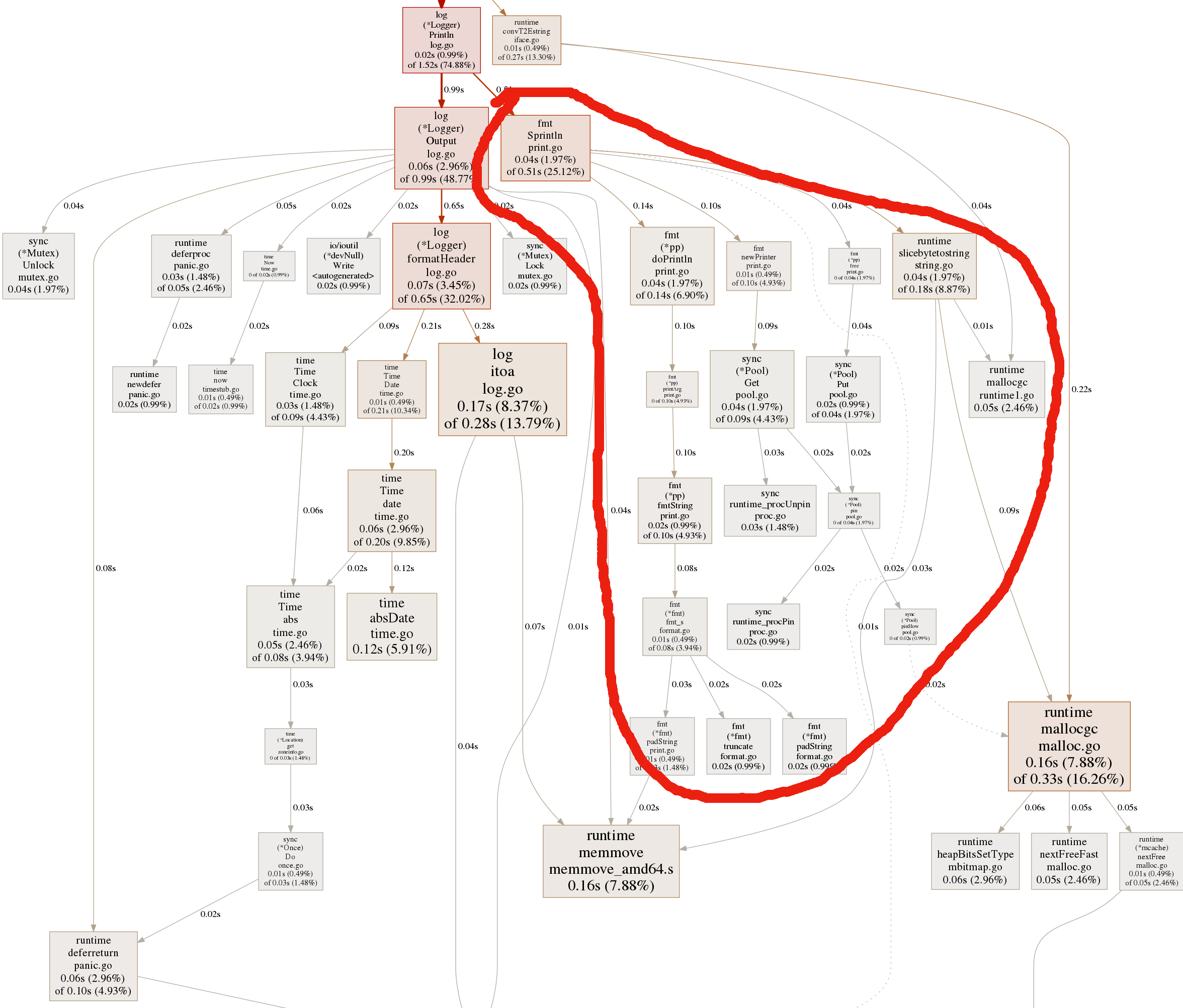
If we look into the cpu profile from this benchmark -
Its hard to figure out what’s going on. But the key takeaway here is that huge portion of the function calls circled in red is what’s happening from the Sprintln call. If you zoom in to the attached svg here, you can see lot of time being spent on getting and putting back the buffer to the pool and some more time being spent on formatting the string.
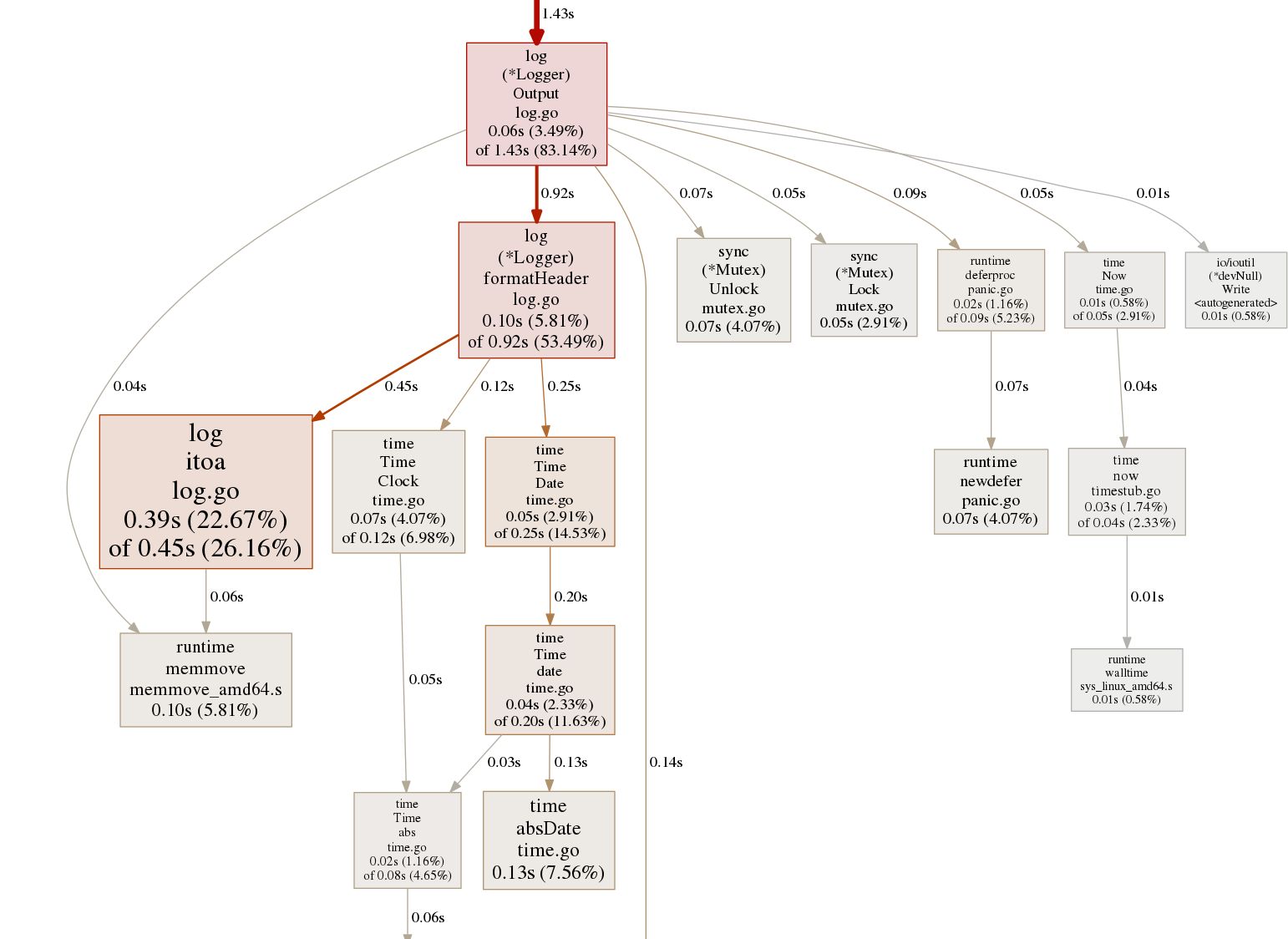
Now, if we compare this to a benchmark by directly calling the Output function -
func BenchmarkLogger(b *testing.B) {
logger := log.New(ioutil.Discard, "[INFO] ", log.LstdFlags)
errmsg := "hi this is an error msg"
for n := 0; n < b.N; n++ {
logger.Output(1, errmsg) // 1 is the call depth used to print the source file and line number
}
}
Bam. The entire portion due to the SPrintln call is gone.
Time to actually compare the 2 benchmarks and see how they perform.
funcBenchmarkLogger(b*testing.B){logger:=log.New(ioutil.Discard,"[INFO] ",log.LstdFlags)testData:=[]struct{teststringdatastring}{{"short-str","short string"},{"medium-str","this can be a medium sized string"},{"long-str","just to see how much difference a very long string makes"},}for_,item:=rangetestData{b.Run(item.test,func(b*testing.B){b.SetBytes(int64(len(item.data)))forn:=0;n<b.N;n++{// logger.Println(str) // Switched between these lines to comparelogger.Output(1,item.data)}})}}
More or less what was expected. It removes the allocations entirely by bypassing the fmt calls. So, the larger of a string you have, the more you save. And also, the time difference increases as the string size increases.
But as you might have already figured out, this is just optimizing a corner case. Some of the limitations of this approach are:
It is only applicable when you just have a single string and directly printing that. The moment you move to creating a formatted string, you need to call fmt.Sprintf and you deal with the pp buffer pool again.
It is only applicable when you are using the log package to write to an underlying writer. If you are calling the methods of the writer struct directly, then all of this is already taken care of.
It hurts readability too. logger.Println(msg) is certainly much more readable and clear than logger.Output(1, msg).
I only had a couple of cases like this in my code’s hot path. And in top-level benchmarks, they don’t have much of an impact. But in situations, where you have a write-heavy application and a whole lot of plain strings are being written, you might look into using this and see if it gives you any benefit.
This is a recount of an adventure where I experimented with some Go assembly coding in trying to optimize the math.Atan2 function.
Some context
The reason for optimizing the math.Atan2 function is because my current work involves performing some math calculations. And the math.Atan2 call was in the hot path. Now, usually I don’t look beyond trying to optimize what the standard library is already doing, but just for the heck of it, I tried to see if there are any ways in which the calculation can be done faster.
And that led me to this SO link. So, there seems to be an FMA operation which does a fused-multiply-add in a single step. That was very interesting. Looking into Go, I found that this is an open issue which is yet to be implemented in the Go assembler. That means, the Go code is still doing normal multiply-add inside the math.Atan2 call. This seemed like something that can be optimized. Atleast, it was worth a shot to see if there are considerable gains.
But that meant, I have to write an assembly module to be called from Go code.
So it begins …
I started to do some digging. The Go documentation mentions how to add unsupported instructions in a Go assembly module. Essentially, you have to write the opcode for that instruction using a BYTE or WORD directive.
I wanted to start off with something simple. Found a couple of good links here and here. The details of how an assembly module works are not necessary to mention here. The first link explains it pretty well. This will be just about how the FMA instruction was utilized to replace a normal multiply-add.
Anyway, so I copied the simple addition example and got it working. Here is the code for reference -
#include "textflag.h"
TEXT ·add(SB),NOSPLIT,$0
MOVQ x+0(FP), BX
MOVQ y+8(FP), BP
ADDQ BP, BX
MOVQ BX, ret+16(FP)
RET
Note the #include directive. You need that. Otherwise, it does not recognize the NOSPLIT command.
Now, the next target was to convert this into adding float64 variables. Now keep in mind, I am an average programmer whose last brush with assembly was in University in some sketchy course. The following might be simple to some of you but this was me -
After some hit and trial and sifting through some Go code, I got to a working version. Note that, this adds 3 variables instead of 2. This was to prepare the example for the FMA instruction.
TEXT ·add(SB),$0
FMOVD x+0(FP), F0
FMOVD F0, F1
FMOVD y+8(FP), F0
FADDD F1, F0
FMOVD F0, F1
FMOVD z+16(FP), F0
FADDD F1, F0
FMOVD F0, ret+24(FP)
RET
Then I had a brilliant(totally IMO) idea. I could write a simple floating add in Go, do a go tool compile -S, get the generated assembly and copy that instead of handcoding it myself ! This was the result -
Alright, so far so good. Only thing remaining was to add the FMA instruction. Instead of adding the 3 numbers, we just need to multiply the first 2 and add it to the 3rd and return it.
Looking into the documentation, I found that there are several variants of FMA. Essentially there are 2 main categories, which deals with single precision and double precision values. And each category has 3 variants which do a permutation-combination of which arguments to choose, when doing the multiply-add. I went ahead with the double precision one because that’s what we are dealing with here. These are the variants of it -
VFMADD132PD: Multiplies the two or four packed double-precision floating-point values from the first source operand to the two or four packed double-precision floating-point values in the third source operand, adds the infi-nite precision intermediate result to the two or four packed double-precision floating-point values in the second source operand, performs rounding and stores the resulting two or four packed double-precision floating-point values to the destination operand (first source operand).
VFMADD213PD: Multiplies the two or four packed double-precision floating-point values from the second source operand to the two or four packed double-precision floating-point values in the first source operand, adds the infi-nite precision intermediate result to the two or four packed double-precision floating-point values in the third source operand, performs rounding and stores the resulting two or four packed double-precision floating-point values to the destination operand (first source operand).
VFMADD231PD: Multiplies the two or four packed double-precision floating-point values from the second source to the two or four packed double-precision floating-point values in the third source operand, adds the infinite preci-sion intermediate result to the two or four packed double-precision floating-point values in the first source operand, performs rounding and stores the resulting two or four packed double-precision floating-point values to the destination operand (first source operand).
The explanations are copied from the intel reference manual (pg 1483). Basically, the 132, 213, 231 denotes the index of the operand on which the operations are being done. Why there is no 123 is beyond me. I selected the 213 variant because that’s what felt intuitive to me - doing the addition with the last operand.
Ok, so now that the instruction was selected, I needed to get the opcode for this. Believe it or not, here was where everything came to a halt. The intel reference manual and other sites all mention the opcode as VEX.DDS.128.66.0F38.W1 A8 /r and I had no clue what that was supposed to mean. The Go doc link showed that the opcode for EMMS was 0F, 77. So, maybe for VFMADD213PD, it was 0F, 38 ? That didn’t work. And no variations of that worked.
Finally, a breakthrough came with this link. I wrote a file containing this -
BITS 64
VFMADD213PD xmm0, xmm2, xmm3
Saved it as test.asm. Then after a yasm test.asm and xxd test; I got the holy grail - C4E2E9A8C3. Like I said, I had no idea how was it so different than what the documentation said, but nevertheless decided to move on ahead.
Alright, so integrating it within the code. I got this -
Perfect. Now I just need to write my own atan2 implementation with the fma operations replaced with this asm call. I copied all of the code from the standard library for the atan2 function, and replaced the multiply-additions with an fma call. The brunt of the calculation actually happens inside a xatan call.
Did some sanity checks to verify the correctness. Everything looked good. Now time to benchmark and get some sweet perf improvement !
And, here was what I saw -
go test -bench=. -benchmem
BenchmarkAtan2-4 100000000 23.6 ns/op 0 B/op 0 allocs/op
BenchmarkMyAtan2-4 30000000 53.4 ns/op 0 B/op 0 allocs/op
PASS
ok asm 4.051s
The fma implementation was slower, much slower than the normal multiply-add. Trying to get deeper into it, I thought of benchmarking just the pure fma function with a normal native Go multiply-add. This was what I got -
go test -bench=. -benchmem
BenchmarkFMA-4 1000000000 2.72 ns/op 0 B/op 0 allocs/op
BenchmarkNormalMultiplyAdd-4 2000000000 0.38 ns/op 0 B/op 0 allocs/op
PASS
ok asm 3.799s
I knew it! It was the assembly call overhead which was more than the gain I got from the fma calculation. Just to confirm this theory, I did another benchmark where I compared with an assembly implementation of a multiply-add.
go test -bench=. -benchmem -cpu=1
BenchmarkFma 1000000000 2.65 ns/op 0 B/op 0 allocs/op
BenchmarkAsmNormal 1000000000 2.66 ns/op 0 B/op 0 allocs/op
PASS
ok asm 5.866s
Clearly it was the function call overhead. That meant if I implemented the entire xatan function in assembly which had 9 fma calls, there might be a chance that the gain from fma calls were actually more than the loss from the assembly call overhead. Time to put the theory to test.
After a couple of hours of struggling, my full asm xatan implementation was complete. Note that there are 8 fma calls. The last one can also be converted to fma, but I was too eager to find out the results. If it did give any benefit, then it makes sense to optimize further. This was my final xatan implementation in assembly.
funcBenchmarkMyAtan2(b*testing.B){forn:=0;n<b.N;n++{myatan2(-479,123)// same code as standard library, with just the xatan function swapped to the one above}}funcBenchmarkAtan2(b*testing.B){forn:=0;n<b.N;n++{math.Atan2(-479,123)}}
Still slower, but much better this time. I had managed to bring it down from 53.4 ns/op to 25.3ns/op. Note that these are just results from one run. Ideally, good benchmarks should be run several times and viewed through the benchstat tool. But, the point here is that even after writing the entire xatan code in assembly with only one function call it was just comparable enough with the normal atan2 function. That is something not desirable. Until the gains are pretty big enough, it doesn’t make sense to write and maintain an assembly module.
Maybe if someone implements the entire atan2 function in assembly, we might actually see the asm implementation beat the native one. But still I don’t think the gains will be great enough to warrant the cost of writing it in assembly. So until the time issue 8037 is resolved, we will have to make do with whatever we got.
And that’s it !
It was fun to tinker with assembly code. I have much more respect for a compiler now. Sadly, all adventures do not end with a success story. Some adventures are just for the experience
I have been writing open-source software in Go for quite some time now. And only recently, an opportunity came along, which allowed me to write Go code at work too. I happily shifted gears from being a free-time Go coder to full time coding in Go.
All was fine until the last GopherCon happened, where a contributor’s workshop was held. Suddenly, seeing all these people committing code to Go gave me an itch to do something. And immediately within a few days, Fransesc did a wonderful video on the steps to contribute to the Go project on his JustForFunc channel.
The urge was too much. With having an inkling of an idea on what to contribute, I atleast decided to download the source code and compile it. Thus began my journey to become a Go contributor !
I started reading the contribution guide and followed along the steps. Signing the CLA was bit of a struggle, because the instructions were slightly incorrect. Well, why not raise an issue and offer to fix it on my own ? That can well be my first CL ! Excited, I filed this issue. It turned out to be a classic n00b mistake. The issue was already fixed in tip, and I didn’t even bother to look. Shame !
Anyways, now that everything was set, I was wading along aimlessly across the standard library. After writing continuous Go code for a few months at work, there were a few areas in the standard library which consistently came up as hotspots in the cpu profiles. One of them was the fmt package. I decided to look at the fmt package and see if something can be done. After an hour or so, something came out.
The fmt_sbx function in the fmt/format.go file, starts like this -
func(f*fmt)fmt_sbx(sstring,b[]byte,digitsstring){length:=len(b)ifb==nil{// No byte slice present. Assume string s should be encoded.length=len(s)}
It was clear that the len() call happened twice in case b was nil, whereas, if it was moved to the else part of the if condition, only one of them would happen. It was an extremely tiny thing. But it was something. Eventually, I decided to send a CL just to see what others will say about it.
Within a few minutes of my pushing the CL, Ian gave a +2, and after that Avelino gave a +1. It was unbelievable !
And then things took a darker turn. Dave gave a -1 and Martin also concurred. He actually took binary dumps of the code and examined that there was no difference in the generated assembly at all. Dave had already suspected that the compiler was smart enough to detect such an optimization and overall it was a net loss because the else condition hurt readability at no considerable gain in performance.
The CL had to be abandoned.
But I learnt a lot along the way, adding new tools like benchstat and benchcmp under my belt. Moreover, now I was comfortable with the whole process. So there was no harm in trying again.
A few days back, I found out that instead of doing an fmt.Sprintf() with strings, a string concat is a lot faster. I started searching for a victim, and it didn’t take much time. It was the archive/tar package. The formatPAXRecord function in archive/tar/strconv.go has some code like this -
On changing the last line to - record := fmt.Sprint(size) + " " + k + "=" + v + "\n", I saw pretty significant improvements -
name old time/op new time/op delta
FormatPAXRecord 683ns ± 2% 457ns ± 1% -33.05% (p=0.000 n=10+10)
name old alloc/op new alloc/op delta
FormatPAXRecord 112B ± 0% 64B ± 0% -42.86% (p=0.000 n=10+10)
name old allocs/op new allocs/op delta
FormatPAXRecord 8.00 ± 0% 6.00 ± 0% -25.00% (p=0.000 n=10+10)
The rest, as they say, is history . This time, Joe reviewed it. And after some small improvements, it got merged ! Yay ! I was a Go contributor. From being an average open source contributor, I actually made a contribution to the Go programming language.
This is no way the end for me. I am starting to grasp the language much better and will keep sending CLs as and when I find things to do. Full marks to the Go team for tirelessly managing such a complex project so beautifully.
P.S. For reference -
This is my first CL which was rejected: https://go-review.googlesource.com/c/54952/
And this is the second CL which got merged: https://go-review.googlesource.com/c/55210/
After having read the absolutely wonderful exploring ES6, I wanted to use my newly acquired ES6 skills in a new project. And promises were always the crown jewel of esoteric topics to me (after monads of course :P).
Finally a new project came along, and I excitedly sat down to apply all my knowledge into practice. I started nice and easy, moved on to Promise.all() to load multiple promises in parallel, but then a use case cropped up, where I had to load promises in series. No sweat, just head over to SO, and look up the answer. Surely, I am not the only one here with this requirement. Sadly, most of the answers pointed to using async and other similar libraries. Nevertheless, I did get an answer which just used plain ES6 code to do that. Aww yiss ! Problemo solved.
I couldn’t declare the functions in an array like the example. Because I had a single function. I modified the code a bit to adjust for my usecase. This was how it came out -
'use strict';constload=require('request');letmyAsyncFuncs=[computeFn(1),computeFn(2),computeFn(3)];functioncomputeFn(val){returnnewPromise((resolve,reject)=>{console.log(val);// I have used load() but this can be any async callload('http://exploringjs.com/es6/ch_promises.html',(err,resp,body)=>{if(err){returnreject(err);}console.log("resolved")resolve(val);});});}myAsyncFuncs.reduce((prev,curr)=>{console.log("returned one promise");returnprev.then(curr);},Promise.resolve(0)).then((result)=>{console.log("At the end of everything");}).catch(err=>{console.error(err);});
Not so fast. As you can guess, it didn’t work out. This was the output I got -
1
2
3
returned one promise
returned one promise
returned one promise
At the end of everything
resolved
resolved
resolved
The promises were all getting pre-executed and didn’t wait for the previous promise to finish. What is going on ? After some more time, got this (Advanced mistake #3: promises vs promise factories).
Aha ! So the promise will start to execute immediately on instantiation. And will resolve only when called. So all I had to do was delay the execution of the promise until the previous promise was finished. bind to the rescue !
'use strict';constload=require('request');letmyAsyncFuncs=[computeFn.bind(null,1),computeFn.bind(null,2),computeFn.bind(null,3)];functioncomputeFn(val){returnnewPromise((resolve,reject)=>{console.log(val);// I have used load() but this can be any async callload('http://exploringjs.com/es6/ch_promises.html',(err,resp,body)=>{if(err){returnreject(err);}console.log("resolved")resolve(val);});});}myAsyncFuncs.reduce((prev,curr)=>{console.log("returned one promise");returnprev.then(curr);},Promise.resolve(0)).then((result)=>{console.log("At the end of everything");}).catch(err=>{console.error(err);});
And now -
returned one promise
returned one promise
returned one promise
1
resolved
2
resolved
3
resolved
At the end of everything
Finally :)
Conclusion - If you want to execute promises in series, dont create promises which start executing. Delay their execution untill the previous promise has finished.
Disclaimer: I am in no way an expert in statistics, so much of the details is beyond me. This is just an explanation of my attempt to solve the problem I had.
Recently, I was working with some cool stuff in image processing. I had to extract some shapes after binarizing some images. The final task was to smoothen the contours extracted from the shapes to give it a better feel.
After researching around a bit, the task was clear. All I had to do was resample the points in the contours at regular intervals and draw a spline through the control points. But opencv had no native function to do this. So I had to resort to numpy. Now, another problem in numpy was the data representation. Though opencv uses numpy internally, you have to jump through a couple of hoops to get everything running along smoothly.
Now comes the numpy code to smoothen each contour-
importnumpyimportcv2fromscipy.interpolateimportsplprep,splevsmoothened=[]forcontourincontours:x,y=contour.T# Convert from numpy arrays to normal arrays
x=x.tolist()[0]y=y.tolist()[0]# https://docs.scipy.org/doc/scipy-0.14.0/reference/generated/scipy.interpolate.splprep.html
tck,u=splprep([x,y],u=None,s=1.0,per=1)# https://docs.scipy.org/doc/numpy-1.10.1/reference/generated/numpy.linspace.html
u_new=numpy.linspace(u.min(),u.max(),25)# https://docs.scipy.org/doc/scipy-0.14.0/reference/generated/scipy.interpolate.splev.html
x_new,y_new=splev(u_new,tck,der=0)# Convert it back to numpy format for opencv to be able to display it
res_array=[[[int(i[0]),int(i[1])]]foriinzip(x_new,y_new)]smoothened.append(numpy.asarray(res_array,dtype=numpy.int32))# Overlay the smoothed contours on the original image
cv2.drawContours(original_img,smoothened,-1,(255,255,255),2)
P.S.: Credit has to be given to this SO answer which served as the starting point.
As you can see, data conversion is required to pass to splprep. And then again, when you are appending to the list to overlay on the image.
Hope you found it useful. If you have a better way to achieve the same result, please do not hesitate to let me know in the comments !



{kind=link}